图半监督节点分类之一——相关技术
问题描述
在如今的大数据时代,社会的各个方面时时刻刻产生着大量的数据。很多时候,数据之间并不是独立的,而是建立了方方面面的联系。这种类型的数据被称作“关系型数据”。对于数据间的联系,图是一种有效的表达方式。一些数据间的关系结构,比如语音或文本中的序列结构和图片中的栅格结构,都可以视为一种特殊的图。
作为一个典型的例子,社交网络分析已经被用于朋友推荐、内容推荐和计算广告等具体业务。在基于图的机器学习中,每个样本作为图中的一个节点,样本之间的相似性将作为样本之间的关系反映到图中的边上,相似性越大,边的权重也就越大。
在一些情况下,可以通过节点活动产生的自然关系来构建图,例如社交网络中的关注和转发行为,以及引用网络中的引用关系。这种自然关系提供了节点特征中不存在的附加信息。利用这些信息,研究者可以更好地掌握数据背后的规律并提高模型的推理性能。但是在一些其他情况下,这些产生关系的行为缺失了或者不存在。 一个常用的方法是构建K近邻图(K-Nearest Neighbor Graph, K-NNG)miller1997separators。暴力K近邻图构造方法的计算复杂度为$O(n^2)$,这对于大规模数据集来说并不实用。一些近似方法被提出来,在降低复杂度的同时保持高质量的图结构dong2011efficientzhang2013fast。本文关注的是图已经显式给定的情况。
在一个典型的图结构数据集中,除了图的结构外,还有两个重要的方面:节点的特征和节点的标签。有监督学习方法需要在训练集(标记数据)上训练,然后在测试集上做推断。因此,模型的性能很大程度上受训练集大小的影响。当训练数据不够时,很容易出现过拟合问题,模型的泛化性能不能得到保障。 然而,实际中的样本并不都是有标记的,由于繁重的标注过程,实际上只有极少的样本被标记,大量未知标签的数据每时每刻都在生成。再者,因为网络结构的限制,无法随意地把未标记的样本扔出训练集,这样会照成网络的不完整。由于未标记的样本是很好获得的,在图上做半监督学习是一个很自然并且很重要的任务。
本文研究了基于图的半监督节点分类问题。下图给出了该问题的任务描述:对一个部分标注图中的未标记节点进行分类。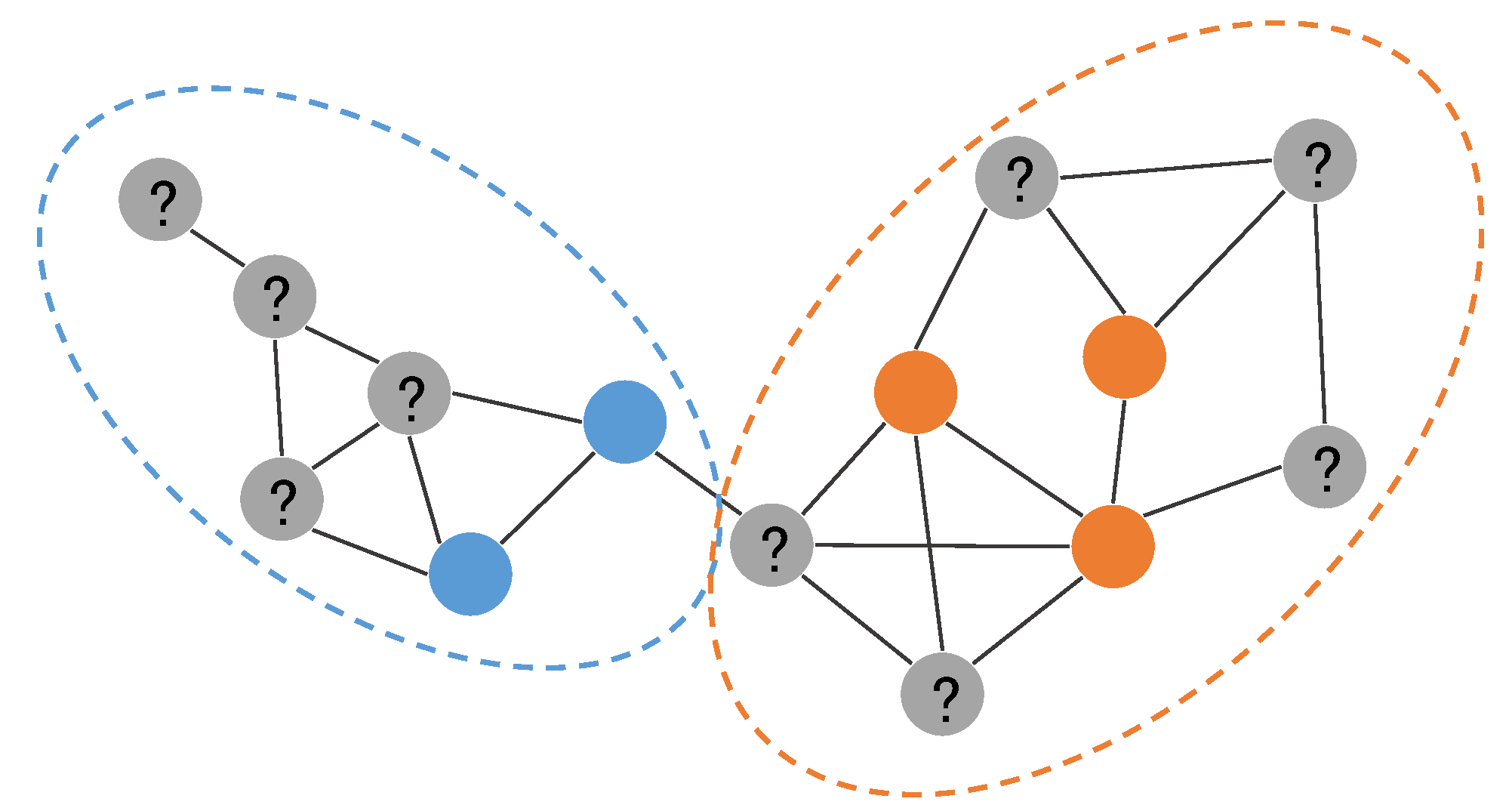
采用半监督学习方法,大量的未标记样本也被利用到模型训练过程中来。事实上,因为网络结构从某种程度上反映了节点之间的相似性,图上大量未标记的样本也能提供有助于分类的信息,比如上图中虚线框所示的社区结构信息,相同社区内的节点倾向于具备相同的类别。借助网络上的社区结构,需要的标记样本数量将会大大较少,分类结果将会更加准确。直接用节点特征训练分类器的传统方法,会受限于特征的质量和训练样本的数目。合理利用网络结构这一异构信息,在少量标记样本下做半监督学习,利用大量的未标记样本,使得模型获得更好的分类性能,是一个很有现实意义和迫切需求的研究工作。
可能的应用场景有:
- 数据标注:极大减少标注成本
- 节点分类:用户画像、图像描述、异常点检测
- 链接预测:推荐系统、网络重构
- 社区发现:人群发现、社会网络分析、广告投放
符号定义
本节首先给出关于半监督图节点分类问题的一些定义和符号表达。
图结构可以表述为$G = (V,E)$,其中$V$为图中节点的集合,$E$为图中边的集合。在实际中,相关方法更多地采用邻接矩阵$A \in \mathbb{R}^{n \times n}$来反映图的结构。在本文处理的问题中,除了图结构以外,图中节点还拥有特征$X$和标签$Y$这两类信息。更加具体地,本文处理的是部分标记的图。令$L$和$U$分别表示标记节点集合和未标记节点集合,并且$L \cup U = V$。对应地,$X^L$ 和 $Y^L$ 为标记节点的特征和标签。一个部分标记属性图的定义如下:
定义一: 部分标记属性图
一个完整部分标记属性图被定义为$G_p = (X^L, X^U, A, Y^L)$,图中节点拥有特征 $X = X^L \cup X^U$ ,部分标记的节点$V^L$还拥有类别标签信息 $Y^L$ 。
基于定义一,给定一个部分标记属性图$G_p$,半监督节点分类的目的是通过学习一个预测函数$f$来推断未标记节点$V^U$的类别标签:
值得注意的是,并不是所有方法都是基于这个完整的部分标记属性图$G_p$,在有些情况下,样本特征矩阵是缺失的。这个时候样本特征矩阵$X$就等同于邻接矩阵$A$,用连接关系这一上下文来代表样本的特征。
不难发现,图半监督方法的核心是通过邻接矩阵来利用未标记样本的信息。在图未知时,邻接矩阵$A$是通过计算节点特征间的相似性得到的相似性矩阵。本文关注的是图已经被显式给出的情况,此时边的权重$a_{ij}$反映了节点$v_i$和节点$v_j$之间的独立于样本特征之外的相似性(自然相关性),边权重越大,节点之间就越相似。不同方法对图结构的利用的一个很重要的不同之处在于利用多大范围的邻居信息,一般方法仅仅只利用直接相连的邻居的信息,这部分仅仅反映图的局部结构。由于实际中图的稀疏性,一阶邻居的信息可能并不能充分的代表节点的上下文,因此二阶邻居甚至更高阶的邻居被考虑进来,这部分信息反映了图的全局结构。本文首先给出一阶近似与二阶近似的定义。
定义二: 一阶近似
一阶近似指的是网络中节点之间的局部成对相似性,但是仅限于通过边连接的节点对。对于每个节点对$(vi, v_j)$,如果$(v_i, v_j) \in E$,节点$v_i$和节点$v_j$之间的一阶近似就是边的权重$a{ij}$,其他情况下一阶近似为0。一阶近似捕获节点之间的直接相邻关系,也就是一阶相邻关系。定义三: 二阶近似
如果令$Nu = {a{u,1}, \cdots, a_{u,|V|}}$表示节点$v_u$与其他节点的一阶近似,那么节点$v_i$和节点$v_j$之间的二阶近似就是$N_i$和$N_j$之间的相似性。二阶近似捕获每对节点之间的二阶关系。一种简单的计算方式是统计两个节点的共同的邻居数目,另一种方式计算从节点$v_i$随机游走到$v_j$的转移概率。
下图,给出了一阶近似与二阶近似对邻居利用范围的示意。图中红色节点是目标节点$v_i$,蓝色节点是其需要汇集信息的一阶和二阶近邻节点。
自然地,模型必须维持一阶近似,因为它意味着现实网络中的两个节点如果被观测到有边相连,那么它们总会在某些方面相似。例如,如果一篇论文引用了另一篇论文,它们应该存在一些共同的主题。直观上,二阶近似假设如果两个节点拥有很多共同的邻居,它们往往是相似的。这样的假设在许多领域已被证明是合理的。例如,在语言学中,如果单词总是被类似的语境所包围,那么它们将会是相似的dash2008context。如果两个人有许多共同的朋友,他们很有可能成为朋友jin2001structure。二阶近似已经被证明是定义一对节点相似性的一个很好的度量,即使这对节点没有直接相连liben2007link,因此二阶近似可以高度丰富节点间的关系。
除了一阶近似和二阶近似外,还有更高阶的近似。结合二阶近似的定义,不难给出高阶近似的定义:
定义四:高阶近似
与二阶近似相比,高阶近似的目的是捕获更大范围的全局结构(节点间的$k$阶关系),比如社团结构。对于节点对$(v_i, v_j)$,他们之间的高阶近似是通过计算两个节点间的$k$阶($k\geq 3$)转移概率。
为了保持一阶近似,目前的一些方法大多通过图拉普拉斯正则化来约束节点之间的特征或者类别分布。对于二阶近似和高阶近似,图编码方法(Graph Embedding)是最近比较流行的方法。需要强调的是,起初的图编码的目的是将单纯的图结构这一信息编码入节点的向量表达,编码过程只采用了图结构,并有利用节点本身的特征。节点带有特征的图叫做属性图,属性图是本文的工作关注的。在属性图中,图编码函数$f_{embed}$不仅仅是将图结构编码进节点的特征表达,节点原本的特征也被利用起来。
下面给出更一般的在属性图上的图编码的定义:
定义五:图编码
给定一个属性图$G=(V,E,X)$,图编码的目的是学习一个映射函数:
$ f{embed}: (G, v_i) \rightarrow g_i \in \mathbb{R}^{d}, \forall i \in [n] $。其中$d\ll |V|$,图编码 $ f{embed} $ 将节点编码到一个低维特征空间并且保持了某些定义在图上的节点间的相似性,比如一阶近似、二阶近似和高阶近似。
图编码的思想是使相似的节点在编码空间上邻近,从而将不同类型的节点区分开。由于其较好的节点特征表示学习性能,图编码方法已经被广泛应用于图结构数据的各个应用场景。
图拉普拉斯正则
在半监督图节点分类任务中,图中节点是部分标记的。基于图的半监督学习通过某种形式的的基于图的正则化将标签信息在图上进行平滑,因此,大多数图半监督学习方法的损失函数具有如下的形式:
其中,$\mathcal{L}_{label} = \sum_{i \in V^L} l(Yi, f(X_i))$ 表示采用损失函数$l$的有监督损失,$\mathcal{L}\{reg}$ 为基于图的正则项, $\lambda$是正则权重参数。这里的$f$就是上节公式中的预测函数,为了简练起见省略了部分标记属性图$G_P$ 。损失函数$l$就是常见的损失函数,比如平方损失、log损失、hinge损失和交叉熵等。不同图半监督学习方法在损失函数上的差异主要体现在预测函数$f$和图正则化的选取。基于图的正则化依赖的假设是:图中相连的节点倾向于拥有相同的类别标签。最常用的是图拉普拉斯正则,其具体表达如下式:
$\Delta = D - A$ 为图$G$的非标准化图拉普拉斯算子, 其中$A$为邻接矩阵(二值或加权矩阵),$ D_{ii} = \sumj A{ij}$ 是一个对角矩阵,反映节点的度信息,$Xi$为节点$v_i$的特征向量。早期的方法是非参数化的,比较著名的是标签传播算法(Label Propagation, LP)zhu2002learningzhu2003semi。标签传播算法迫使$f$与有标记节点的类别$Y^L$一致,$f$是图中未标记节点的标签查找表,可以用封闭形式的解决方案获得, 并且采用上诉公式所示的图拉普拉斯正则,当具有较大边权重$A{ij}$的节点对被预测为具有不同的标签$f(X_i) \neq f(X_j)$时,产生较大的惩罚。ManiRegbelkin2006manifold用支持向量机中的hinge损失来替换LP中的有监督损失。ICAlu2003link通过允许更一般的本地更新来推广标签传播算法。ICA使用以相邻节点的标签作为输入的本地分类器,并且在估计本地分类器和分配新标签之间采用迭代过程。
标签传播算法是在标签层面上利用网络结构的信息,最近比较流行的图编码方法首先在特征层面上利用图结构信息,学习得到节点的低维特征表示,使得网络相连的相似的节点在该特征空间上邻近。图编码方法主要可以分为神经网络方法和矩阵分解方法,但是其损失函数具备同样的形式。对于基于图的正则化,不同方法也有一些细微的不同,但是基于的假设不变,都是促使网络上相连的相似的节点在编码空间上邻近。此时,图拉普拉斯正则变为:
其中$g(\cdot)$为特征编码函数,结合网络结构将原始特征$X$编码到低维空间。与上文图拉普拉斯公式不同的是,图编码方法将正则约束作用在了编码后的特征$g(X_i)$上,而不是推理出的分类结果$f(X_i)$上。图编码的这种处理方式显然更合理,节点间有边相连,自然的反映了节点之间存在必然的某方面的相似性,但是这个相似性是否体现为类别标签一致就不得而知了。约束编码后的特征相似,并不意味着约束分类结果一致,特征相似但是也存在一些细微差别,这些差别可以使相连的两个节点分类为两个不同的类别。本文所提出的三种方法同样也都是基于该图编码方式。
研究现状
基于图的半监督学习是一种典型的半监督学习方法,其将整个数据集映射成一个图,图中的每个点代表一个样本,图中边的权重与样本之间的相似性成正比。 基于图的方法与一般机器学习方法不同的地方在于对图结构这一样本间关系的利用,不同方法从不同角度以不同的方式利用图结构、节点的类别标签和节点的特征,具体可以分为三大类:
- 标签传播方法:标签传播算法(Label Propagation, LP)zhu2003semi将有标记样本的标签信息在图上传播,并在邻近节点的标签上定义图拉普拉斯正则,该正则用于约束具有较大边权重的相邻节点拥有相同的类别。这类方法只使用网络结构和节点的标签。
- 无监督图编码方法:无监督图编码方法利用网络结构和节点的特征来学习节点的特征表示,忽略了节点的标签。当学得编码后,标准有监督学习应用于这些编码特征以训练模型对节点进行分类。
- 基于因式分解的方法
- 基于随机游走的方法
- 基于自动编码机的方法
- 半监督图编码方法: 半监督图编码方法大多采用神经网络模型来进行特征编码。这些方法在有标记样本上计算有监督损失,利用图拉普拉斯正则在所有样本上计算无监督损失。因此,模型训练过程中利用了网络结构、节点特征和节点标签三方面的信息。
- Planetoid模型:单输入双输入神经网络
- SEANO模型:双输入双输出神经网络
- 图卷积神经网络GCN
图编码方法关注于利用邻居特征将节点编码到一个低维空间,学习节点的特征编码(feature embedding),然后基于学得的特征编码构建分类器。 用上下文训练得到的编码能够用来提高相关任务的性能。典型地,从语言模型训练的词编码可以应用于词性标注、情感分类和命名实体识别。 值得注意的是,并不是所有图编码方法都是半监督的。事实上,早期的图编码方法大多是无监督的,这些方法把编码任务和分类任务放在两个不同的模型中,先采用无监督编码学习到节点特征表示,再基于学习到的特征训练分类器。这种流水线的方式使得图编码方法广泛应用于图分析的各类任务,比如节点分类bhagat2011node、链接预测liben2007link、社团检测cavallari2017learning、推荐系统yu2014personalized和可视化maaten2008visualizing。但是这种方式在训练过程中缺乏有监督信息的调整,编码得到的特征不是针对类别标签的,可能使不同类别的节点在特征空间上还是难以分开。近期的一些图编码方法,将编码和分类这两个任务合并在一个统一的端到端模型中,提出半监督图编码方法。实验结果表明,在图节点分类任务上,半监督图编码只需要极少比例的标记样本就能取得不错的效果。接下来具体对这两类图编码方法进行介绍。
无监督图编码
根据编码过程利用的信息,无监督图编码又可以分为两类:一类只利用网络结构$A$,另一类在利用网络结构$A$的同时,也考虑节点本身特征属性$X$的影响。早期图编码方法大多数为第一类,其目的是将图结构进行编码,使得编码后的特征保持原图的连接关系,即连接越紧密的节点和局部结构越相似的节点在编码后的特征空间上越邻近。下图给出了一个简单的示意。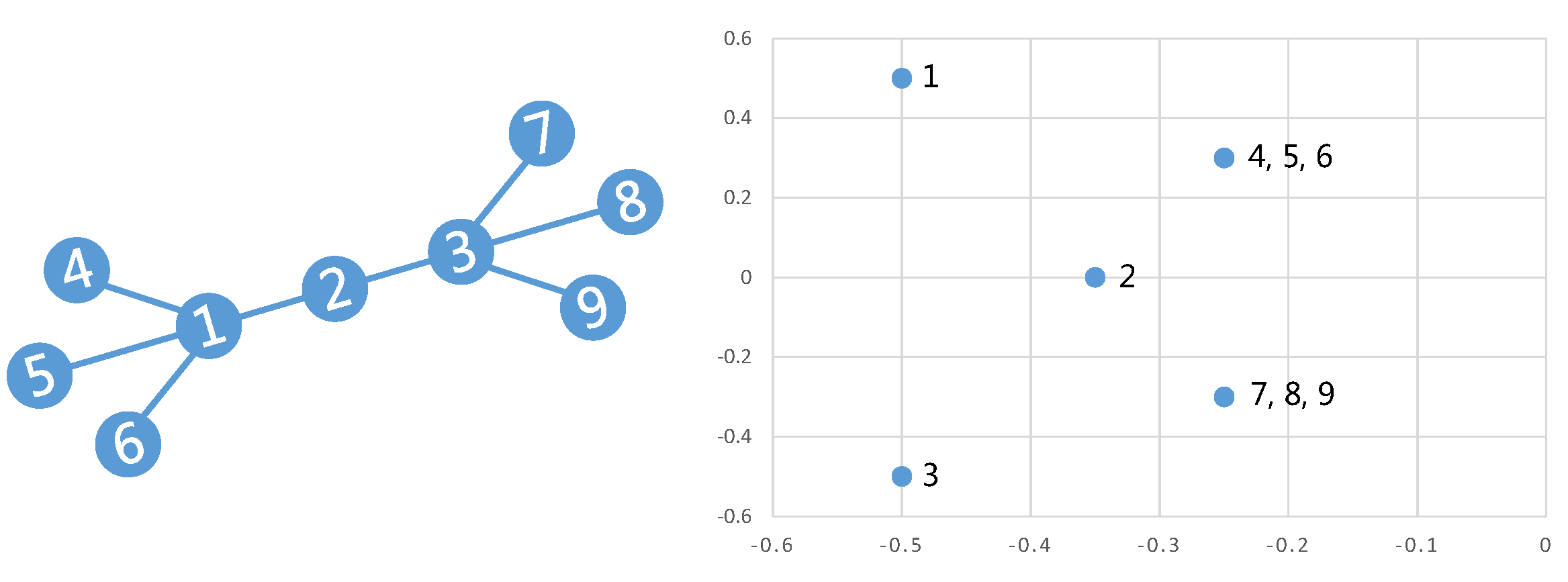
图中不同结构的节点被编码到二维空间上的不同位置。节点4、5和6有相同的图结构,因此被编码到相同的位置。节点1和节点3的局部图结构也相同,但是其分别属于两个社团,因此编码结果分别分布在节点2的两侧,并各自与同社团中的节点邻近(比如节点1和节点4)。如果按社团对节点进行分类,平行于横轴画两条直线就可以将节点分为3类;如果按局部结构对节点进行分类,平行于纵轴画两条线也可以很好的将节点分开。因此,图编码可以学习到效果很好的节点特征,得到的特征也更有解释性,因此广泛用于可视化等应用。接下来,本文分别介绍这两类无监督图编码方法的一些典型工作。
基于因式分解的方法将节点间的连接关系表述为矩阵的形式,并且通过分解该矩阵来获得编码。用来表达连接关系的矩阵可以是邻接矩阵、拉普拉斯矩阵、节点转移概率矩阵和Katz相似性矩阵等。不同的分解该表达矩阵的方法根据矩阵性质的不同而不同。如果获得的矩阵是半正定的,例如拉普拉斯矩阵,就可以使用特征值分解。对于非结构矩阵,可以使用梯度下降法在线性时间复杂度上得到编码结果。
局部线性编码(Locally Linear Embedding, LLE)假设在特征空间上每个节点的特征是其邻居特征的线性加和。如果采用邻接矩阵$A$表达图中节点间的连接权重,并且采用$H_i$来表达节点$v_i$的编码,那么该假设可以表述为:
因此,为了得到编码$H^{N \times d}$,可以最小化下式:
为了去除退化解,编码的方差被限制为$\frac{1}{N} H^T H = I$。为了进一步消除平移不变性,编码被中心化:$\sumi H_i = 0$ 。 上述约束优化问题可以归结为一个特征值问题,其解是取稀疏矩阵$(I-A)^T(I-A)$底部的$d+1$个特征向量,并丢弃对应于最小特征值的特征向量。
不同于LLE的假设,拉普拉斯特征映射(Laplacian Eigenmaps)的目的是在边权$A{ij}$较高时保持这两个节点在编码上紧密。此时,其最小化的目标函数为 :
其中$L$为图的拉普拉斯矩阵,通过取归一化拉普拉斯$L_{norm} = D^{-1/2} L D^{-1/2}$ 的最小的d个特征根对应的特征向量即可得到问题的解。
因式分解(Graph Factorization, GF)提出另一种损失函数,约束两个节点编码结果的距离与连接权重一致:
其中$\lambda$为正则化系数。
GraRepcao2015grarep将节点间转移概率定义为$T = D^{-1}A$,并引入$k$阶概率转移矩阵
为了减少误差和方便计算,GraRep通过 $A^k$ 计算得到正值 $k$ 阶对数概率矩阵 $X^k$ ,并采用奇异值分解(SVD)来求解目标函数 $ \Vert X^k - H^k_i H^k_j \Vert^2_F $ ,得到$k$阶特征编码。最后将所有$H^k_i$合并得到节点$v_i$的最终编码$H_i$。
HOPEou2016asymmetric采用了相似的目标函数来保持高阶近似,$ \Vert S - H_i H_j\Vert^2_F $。 $S$为相似度矩阵,通过对其的计算来保持高阶近似。HOPE采用了一些流行的近似度度量方法进行实验。它发现图中的许多高阶邻近度量可以反映不对称传递性,此外,它们大多共享一个通用公式,这将有助于近似这些近似值:$S = M_g^{-1} \cdot M_l$,其中$M_g$和$ M_l$都是稀疏矩阵。这使得HOPE能够利用广义奇异值分解来有效的求解并得到编码结果。
受word2vecmikolov2013distributed成功的影响,目前越来越多的研究关注于利用类似skip-gram的模型来做图编码。Skip-gram是一种softmax的变种,给定一个样本和其上下文,skip-gram的目标通常是最小化预测上下文的log损失,其中预测上下文利用的是样本的编码作为输入。具体地,设${(i,c)}$是样本$i$和其上下文$c$的组合对的集合,log损失函数能写成:
其中,$\mathcal{C}$是所有可能上下文的集合,$w$是模型参数,$e_i$是样本$i$的编码。Skip-gram模型最开始用于学习词的向量表示,也就是word2vec。在word2vec中,每个训练对$(i,c)$,表示此时要去估计样本$i$的编码,上下文 $c$ 是词$i$在序列中给定窗口内的词,上下文集合空间$\mathcal{C}$为语料库中所有的词。目前许多基于随机游走的方法采用skip-gram模型来学习图节点编码。DeepWalkperozzi2014deepwalk使用节点的编码来预测其在图中的上下文,其上下文是通过随机游走生成的。对于每个训练对$(i,c)$,样本$i$为当前节点,$c$为样本$i$在一定窗口大小的邻居中采用随机游走采样生成的序列,也就是说c的长度是固定的,为窗口的大小。LINEtang2015line扩展了DeepWalk,使其具备多个上下文空间$\mathcal{C}$,用于建模一阶和二阶近似。Node2vecgrover2016node2vec采用带偏置的随机游走,在宽度优先(BFS)和深度优先(DFS)搜索之间提供权衡,因此可生成比DeepWalk更高质量和更丰富信息的编码。选择合适的平衡可以使node2vec保留社区结构以及节点之间的结构对等性。
虽然类似skip-gram的模型最近获取了很大的关注,其他神经网络上的方法同样也被扩展到图的编码中来,比如自动编码机(Autoencoder)。自动编码机是一种典型的无监督神经网络,主要用于高维数据降维和特征学习,已经在各种各样的实际问题中得到了广泛的应用。SDNE(Structural Deep Network Embedding)wang2016structural采用自动编码机来对网络中节点进行编码。
在SDNE中,$x_i = A_i$为邻接矩阵$A$的第$i$行,反映节点$v_i$的网络结构向量。通过在$x_i$上施行自动编码机,使得学到的编码$h_i = y_i^{(K)}$能够保持高阶依赖。因为自动编码机约束输出$\widehat{x_i}$与输入$x_i$一致,这使得编码$h_i$能够推理节点的上下文(网络连接关系),从而保持高阶依赖。不难看出,SDNE在一般自动编码机的基础上,加上了网络结构的约束。这里采用的约束是之前介绍的拉普拉斯特征映射(Laplacian Eigenmaps),约束网络上相近的节点有相近的编码结果。因此,SDNE能同时保持一阶近似和高阶近似,其损失函数为:
其中$\mathcal{L}_{2nd}$对原始的自动编码机的损失做了一定修改,引入惩罚项$B$, 对非零元素的重构误差施加了比零元素更多的惩罚,使得模型更容易重构$X$中的1而不是0。对于$B$,SDNE的定义为:如果 $A{ij} = 0$,$b{ij} = 1$,否则$b_{ij} = \beta > 1$。设计B的出发点是,有边相连表示两点相似,但是没有边相连,不一定代表其不相似。这样一来就能重构高阶邻居的结构信息。 与SDNE直接在邻接矩阵上施行自动编码机不同的是,DNGRcao2016deep结合了随机游走和自动编码机来完成图编码。DNGR首先利用随机游走方法生成带有高阶图结构信息的表达矩阵,然后计算PPMI(positive pointwise mutual information,一种词向量表达方式)矩阵,最后在PPMI矩阵的基础上利用自动编码机替换SVD得到最终的编码结果。
以上第一类无监督图编码方法在编码过程中没有用到节点的特征属性,只编码了网络结构。然而,在实际中,网络中节点往往拥有丰富的信息,比如社交网络中用户发布的微博内容。节点的特征属性更准确的反映了节点的信息,这对于节点的分类任务尤为重要。TADWyang2015network认识到这一点,同时将网络结构和节点特征进行编码。TADW证明了DeepWalk本质上等同于矩阵分解,并在矩阵分解的框架下将节点的文本特征合并到网络表示学习中。
以上无监督图编码方法固然有其普适性等优点,但在图节点分类任务上,它们并没有将节点的标签信息用作编码,而且分类器的训练是在编码的学习之后。所以编码的结果并不是针对该特定的任务的,这也导致该类方法在图节点分类任务上并未达到最先进的结果。
半监督图编码
很多应用被建模和分析为属性图,其中节点表示具备特征的实体,边表示实体之间的交互或关系。在许多情况下,人们还知道属性图中某些节点的标签。这种网络提供了更多的信息,但分析起来也更具挑战性。半监督图编码方法就是在这种情况下进行图编码与节点分类任务。此类方法与前一小节的无监督图编码方法最大的不同有两点:(1)通过集成异构信息(包括图结构、节点特征和部分可用标签)来学习图编码;(2)将图编码和分类这两个过程构建在一个统一的模型中,统一训练,相互补充与调整。
Planetoidyang2016revisiting为图中每个节点训练一个特征编码来联合预测图中的类别标签和邻域上下文。具体地,Planetoid提出了直推(transductive)和归纳(inductive)两种形式的半监督模型,前者假定学习过程中所考虑的未标记样本是待预测数据(图中已观测到的节点,基于“封闭世界”),学习的目的就是在这些未标记样本上获得最优泛化性能,而后者假定训练数据中的未标记样本并非仅仅是待预测数据(包括未观测的节点,基于“开放世界”)。下图给出了这两种方式的网络结构。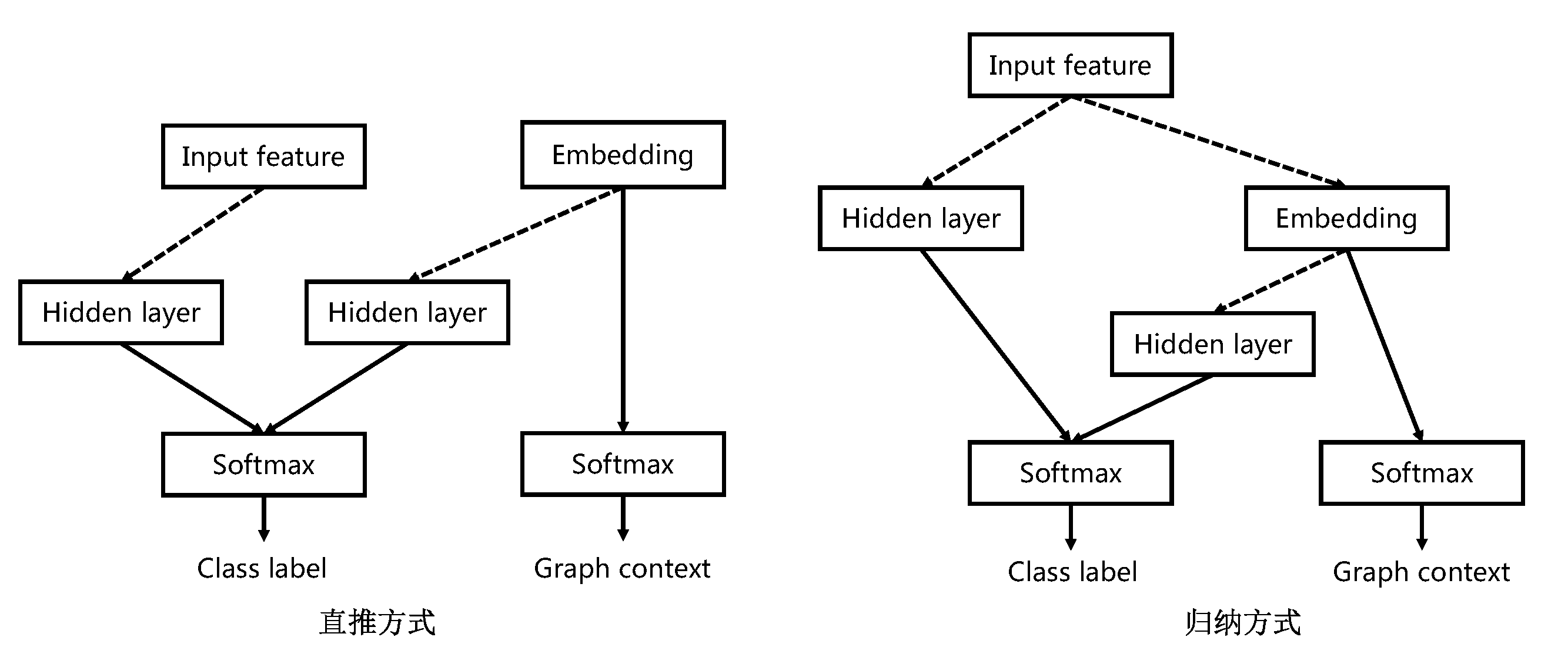
图中直线箭头表示直接相连,虚线箭头表示一个或者多个前馈层。在直推方式中,类别标签由学习的编码和输入的特征向量同时决定。但是在归纳方式中,未标记样本的编码并不能提前学习到,只有在图中观测到的节点才能学习到,因此归纳方式对直推方式的结构做了点修改,将编码定义为特征向量的的参数化函数并且类别标签只依赖于特征向量,这样便可以对训练中未观测到的样本做出预测。
SEANOliang2017seano拥有相似的模型结构,不同的是SEANO设计了一个双输入双输出深度神经网络来归纳学习节点编码。其网络结构见下图。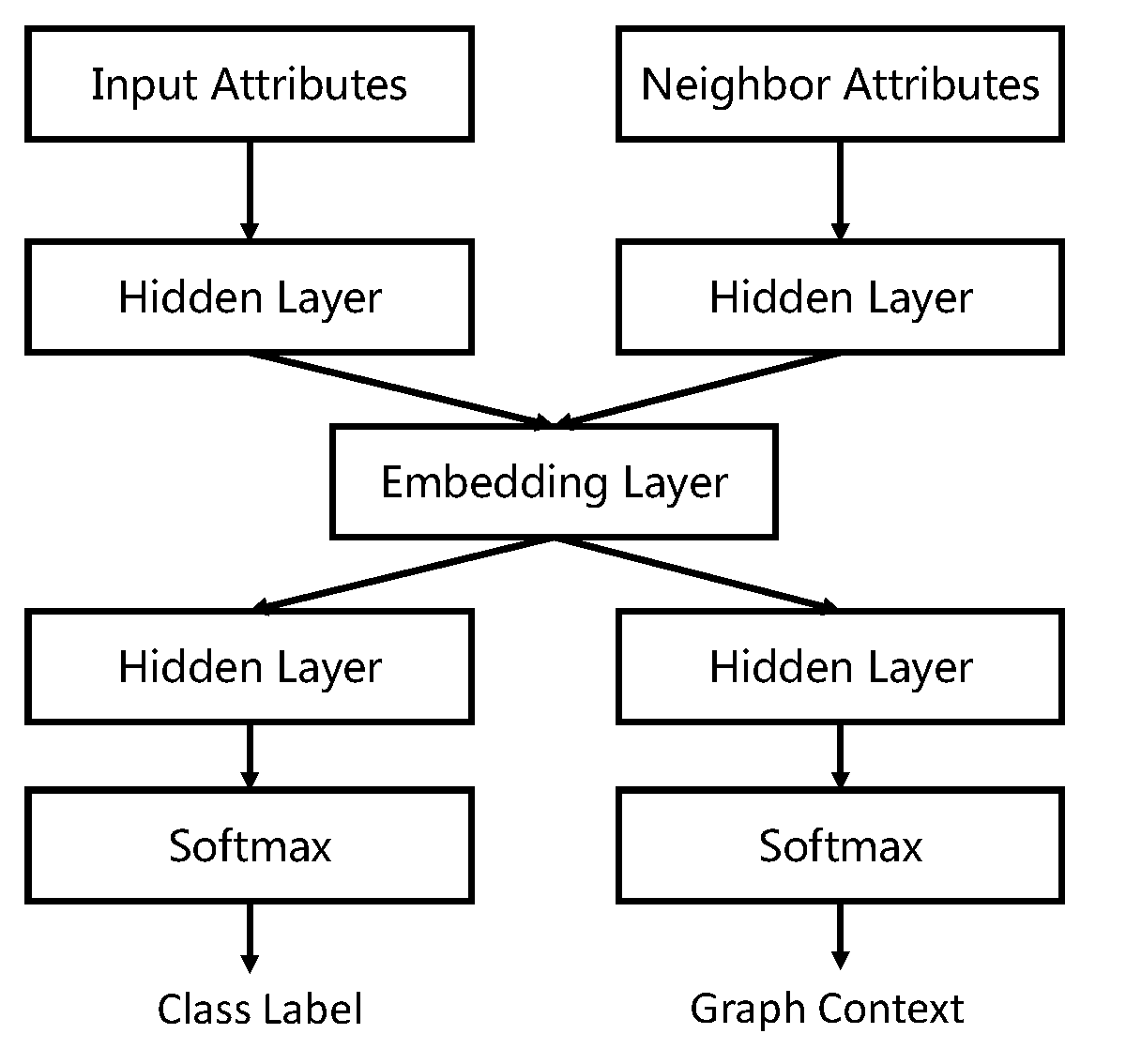
在这里,输入不仅仅是当前节点的特征,还有该节点邻居的特征的加权求和。他们通过相同的一组非线性映射函数,并通过加权求和在编码中进行聚合。 图中的左输出层预测输入节点的类标签,而右输出层产生网络输入的上下文,两者通过共享编码层使得得到的编码能捕获节点特征、网络结构和类别标签三个方面的信息。但是这里有两个输出层,需要分步进行调整,对模型的训练造成了一定不便。
借鉴卷积神经网络的思想,将节点周围的一阶邻居看成其感受野,GCNkipf2016semi提出了一种直接在图上操作的卷积神经网络的有效变体。这是一种简单有效的基于神经网络的分层传播规则。GCN的核心是其卷积方式,具体的卷积过程为:
其中$W^{l}$ 为第$l$层的模型参数,$H^{l}$为第$l$层的输出,$\widehat{A}$的为采用了再归一化技巧后的图拉普拉斯矩阵。具体地,$ \widehat{A} = \widetilde{D}^{ -\frac{1}{2} } \widetilde{A} \widetilde{D}^{ -\frac{1}{2} }$, 其中,$\widetilde{A} = A + IN $,$\widetilde{D}\{ii} = \sumj \widetilde{A}{ij}$。 该卷积将每个点的特征变换成了自己和邻居的特征的加权求和,即$\widehat{A}X$。由于$\widehat{A}$中所有元素的值都小于1,$\widehat{A} X$ 的意义就是在特征空间上节点向其邻居所在的方向加权移动。理想情况下,如果一个节点特征不好分,但是其邻居都远离分界面,那么该点向邻居的移动会使其远离分界面,变得可分。所以$\widehat{A} X$ 使得节点的特征与邻居的特征的差异性一定程度减小,也就是做了局部平滑。基于上式,GCN提出了一个两层的半监督神经网络模型:
第一层用来做编码,第二层用来做分类。相比于SEANO,GCN更加简单有效而且同时利用了部分标记的标签和网络结构。
值得注意的是,GCN只需要少量的标记样本就能在整个网络上取得很好的分类结果。
miller1997separators. MILLER G L, TENG S H, THURSTON W, et al., 1997. Separators for sphere-packings and nearest neighbor graphs[J]. Journal of the ACM (JACM), 44(1): 1–29. ↩
dong2011efficient. DONG W, MOSES C, LI K, 2011. Efficient k-nearest neighbor graph construction for generic similarity measures[C]//Proceedings of the 20th international conference on World wide web. ACM: 577–586. ↩
zhang2013fast. ZHANG Y M, HUANG K, GENG G, et al., 2013. Fast knn graph construction with locality sensitive hashing[C]//Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer: 660–674. ↩
bhagat2011node. BHAGAT S, CORMODE G, MUTHUKRISHNAN S, 2011. Node classification in social networks[M]//Social network data analytics. Springer: 115–148. ↩
liben2007link. LIBEN-NOWELL D, KLEINBERG J, 2007. The link-prediction problem for social networks[J]. journal of the Association for Information Science and Technology, 58(7): 1019–1031. ↩
cavallari2017learning. CAVALLARI S, ZHENG V W, CAI H, et al., 2017. Learning community embedding with community detection and node embedding on graphs[C]//Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. ACM: 377–386. ↩
yu2014personalized. YU X, REN X, SUN Y, et al., 2014. Personalized entity recommendation: A heterogeneous information network approach[C]//Proceedings of the 7th ACM international conference on Web search and data mining. ACM: 283–292. ↩
maaten2008visualizing. MAATEN L V D, HINTON G, 2008. Visualizing data using t-sne[J]. Journal of machine learning research, 9(Nov): 2579–2605. ↩
cao2015grarep. CAO S, LU W, XU Q, 2015. Grarep: Learning graph representations with global structural information[C]//Proceedings of the 24th ACM International on Conference on Information and Knowledge Management. ACM: 891–900. ↩
ou2016asymmetric. OU M, CUI P, PEI J, et al., 2016. Asymmetric transitivity preserving graph embedding[C]//Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining. ACM: 1105–1114. ↩
mikolov2013distributed. MIKOLOV T, SUTSKEVER I, CHEN K, et al., 2013. Distributed representations of words and phrases and their compositionality[J]. neural information processing systems: 3111–3119. ↩
dash2008context. DASH N S, 2008. Context and contextual word meaning.[J]. SKASE Journal of Theoretical Linguistics. ↩
jin2001structure. JIN E M, GIRVAN M, NEWMAN M E, 2001. Structure of growing social networks[J]. Physical review E, 64(4): 046132. ↩
zhu2002learning. ZHU X, GHAHRAMANI Z, 2002. Learning from labeled and unlabeled data with label propagation[Z]. Citeseer ↩
zhu2003semi. ZHU X, GHAHRAMANI Z, LAFFERTY J D, 2003. Semi-supervised learning using gaussian fields and harmonic functions[C]//Proceedings of the 20th International conference on Machine learning (ICML-03). 912–919. ↩
belkin2006manifold. BELKIN M, NIYOGI P, SINDHWANI V, 2006. Manifold regularization: A geometric framework for learning from labeled and unlabeled examples[J]. Journal of machine learning research, 7(Nov): 2399–2434. ↩
lu2003link. LU Q, GETOOR L, 2003. Link-based classification[C]//Proceedings of the 20th International Conference on Machine Learning (ICML-03). 496–503. ↩
perozzi2014deepwalk. PEROZZI B, AL-RFOU R, SKIENA S, 2014. Deepwalk: Online learning of social representations [C]//Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM: 701–710. ↩
tang2015line. TANG J, QU M, WANG M, et al., 2015. Line: Large-scale information network embedding[C]//Proceedings of the 24th International Conference on World Wide Web. [S.l.]: International World Wide Web Conferences Steering Committee: 1067–1077. ↩
grover2016node2vec. GROVER A, LESKOVEC J, 2016. node2vec: Scalable feature learning for networks[C]//Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining. ACM: 855–864. ↩
wang2016structural. WANG D, CUI P, ZHU W, 2016. Structural deep network embedding[C]//Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining. ACM: 1225–1234. ↩
cao2016deep. CAO S, LU W, XU Q, 2016. Deep neural networks for learning graph representations.[C]//AAAI. 1145–1152. ↩
yang2015network. YANG C, LIU Z, ZHAO D, et al., 2015. Network representation learning with rich text information. [C]//IJCAI. 2111–2117. ↩
yang2016revisiting. YANG Z, COHEN W W, SALAKHUTDINOV R, 2016a. Revisiting semi-supervised learning with graph embeddings[J]. arXiv preprint arXiv:1603.08861. ↩
liang2017seano. LIANG J, JACOBS P, PARTHASARATHY S, 2017. Seano: semi-supervised embedding in attributed networks with outliers[J]. arXiv preprint arXiv:1703.08100. ↩
kipf2016semi. KIPF T N, WELLING M, 2016. Semi-supervised classification with graph convolutional networks[J]. arXiv preprint arXiv:1609.02907. ↩
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!