快手语音处理单元mGRU
快手本次在Interspeech 2018上的文章基于GRU提出了新的RNN单元mGRU及其变体mGRUIP,来又快又准的处理语音信息。
论文:Gated Recurrent Unit Based Acoustic Modeling with Future Context
原文摘要:
The use of future contextual information is typically shown to be helpful for acoustic modeling. However, for the recurrent neural network (RNN), it’s not so easy to model the future temporal context effectively, meanwhile keep lower model latency. In this paper, we attempt to design a RNN acoustic model that being capable of utilizing the future context effectively and directly, with the model latency and computation cost as low as possible. The proposed model is based on the minimal gated recurrent unit (mGRU) with an input projection layer inserted in it. Two context modules, temporal encoding and temporal convolution, are specifically designed for this architecture to model the future context. Experimental results on the Switchboard task and an internal Mandarin ASR task show that, the proposed model performs much better than long short-term memory (LSTM) and mGRU models, whereas enables online decoding with a maximum latency of 170 ms. This model even outperforms a very strong baseline, TDNN-LSTM, with smaller model latency and almost half less parameters.
重点:
- 提出了一种能利用下文信息的门控循环单元,同时保持模型的低延迟性。
- 采用了只包含更新门的最小门控循环单元(mGRU)
- 提出了两种上下文模块,时间编码和时间卷积
在处理语音信息中,利用下文信息在语音识别和关键词识别等任务中非常重要,很多时候语音识别不能仅考虑当前话语的信息,我们还需要一定长度的后文信息才能降低口音和连读等协同发音的影响。 但是这里存在一个问题是,语音处理需要快,如果采用一般的双向LSTM,延迟太大了,因为需要等一个句子说完才能反向过程,这样延迟是整句话,显然行不通。
所以,为了降低延迟并提高计算效率,快手的李杰博士等修改基础的GRU单元,添加上下文,提出只包含更新门的最小门控循环单元mGRU(minimal gated recurrent unit)。进一步地,为了减少模型参数和计算量,他们在mGRU中加入了一个降维特征映射层,提出了mGRUIP(input projection layer),先将高维特征压缩为低维,然后在低维特征上发生实际的运算,再恢复到应有的高维特征。
下面具体对这两个模型进行介绍
GRU
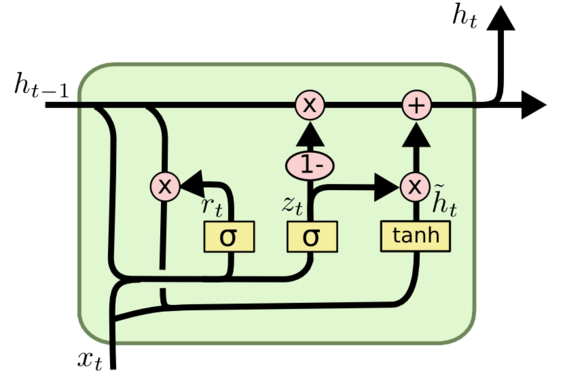
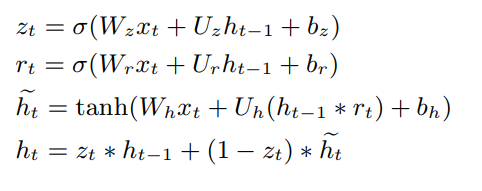
mGRU
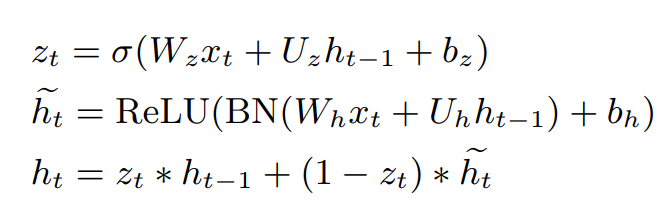
mGRU舍弃了重置门,将更新门中tanh换成了RuLU, 相当于令 GRU 中的重置门恒等于 1。
但是如果网络的每一层神经元都非常多,那么 mGRU 的计算量还是非常大,且随着神经元数量的增加计算成线性增长。这就限制了 mGRU 在大型网络和大规模场景中的应用。因此李杰等研究者进一步提出了带输入映射的 mGRUIP。
mGRUIP
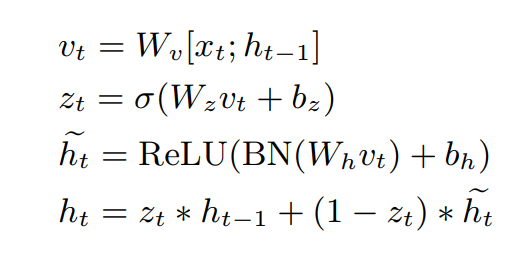
直观的给出这两种单元的结构示意图
以上还OK,接下来将上下文信息加入mGRUIP让我耳目一新,开了思路
在文中,提出两种上下文模块(下文?):时间编码和时间卷积。
先说时间编码,未来帧的语境信息会编码为定长的表征并添加到输入映射层中,以下是其模型结构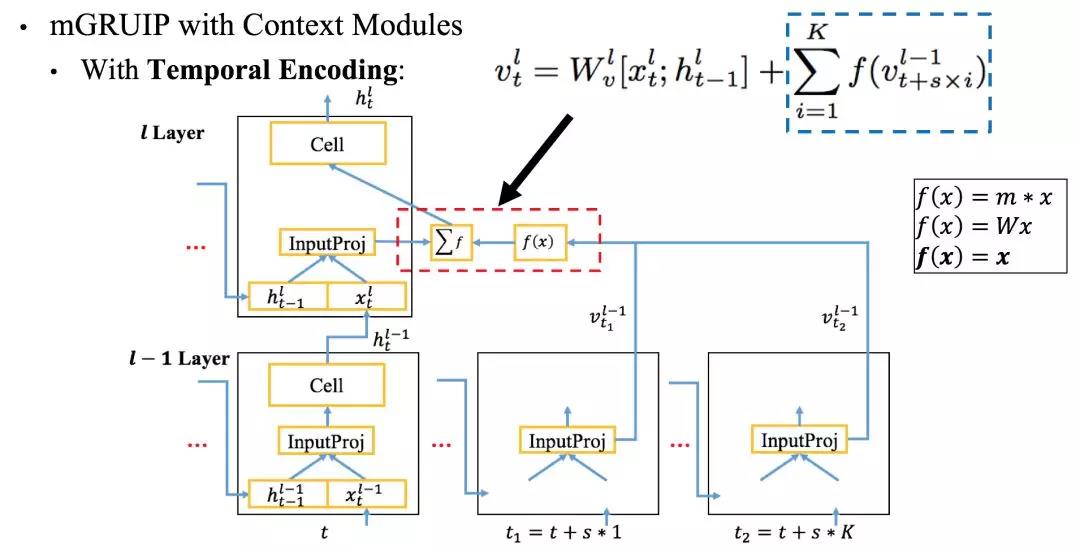
每个单元,代表一帧,它接受K步未来帧的信息,这个过程类似LSTM和CRF,通过K阶关系来降低延迟(相比于整个句子,延迟是无法避免的)。这里厉害之处在于想到这样的单元连接关系来建议依赖,开了思路了。
如上所示转换函数 $f(x)$ 一般可以是数乘、矩阵乘法或者是恒等函数,但快手在实验中发现恒等函数在性能上要更好一些,所以它们选择了
$f(x)=x$,不做处理直接相加。
然后是时间卷积,时间卷积修改其实是上文的转换函数$f(x)$,将所需要的前层输出拼接在一起,通过一个映射层来得到结果。具体如下
总结
这种横向连接多个GRU单元的模式,我在图半监督节点分类的任务重也使用过,提出了GraphGRU, 也是汇聚周围的k阶信息,但是我仅仅只用了加权求和,也考虑过attention,但是会增加计算量,没有像这篇文章做得深究这一块,惭愧。其次,GRU单元的设计也不拘一格,门该减就得减,这也是我一直疑惑的地方,一个门足够了,涨知识了。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!