推荐系统学习笔记
最近对以前学习推荐系统的知识点笔记的一个汇总。
概念
你需要推荐系统吗?
- 看看产品的目的:建立越多连接越好。
- 看产品现有的连接:产品的数量
一个简单指标
分子是增加的连接数,分母是增加的活跃用户数和增加的有效物品数。
如果增加的连接数主要靠增加的活跃用户数和增加的物品数贡献,则该值较小,不适合加入推荐系统。反之,如果增加的连接数和新增活跃用户和物品关系不大,说明连接数已经有自发生长的趋势,适合加入推荐系统加速这个过程。
推荐系统的问题/任务
- 评分预测
- 行为预测
评分预测
显示打分,目标减小预测分数与实际分数之间的误差,回归问题。
评价标准:RMSE、MAE
评分预测存在的问题:
- 数据不易收集
- 数据质量不能保证
- 评分分布不稳定
显示反馈很少,更多的是隐式反馈,通常为各类用户行为。行为预测更多地利用这部分数据。
行为预测
隐式反馈:登陆刷新、购买、收藏、浏览、点击等
行为预测有两种方式:
- 直接预测用户行为:CTR预估
- 预测物品的相对排序:learning2rank
隐式数据的好处:
- 比显式更加稠密
- 隐式更加代表用户的真实想法
- 隐式反馈常常和模型的目标函数关联更密切,也因此通常更容易在 AB 测试中和测试指标挂钩。
推荐系统中几个普遍的问题
- 冷启动问题
- 探索与利用问题:Exploit 和 Explore (EE问题)
- 安全问题
- 给出不靠谱的推荐结果,影响用户体验并最终影响品牌形象;
- 收集了不靠谱的脏数据,这个影响会一直持续留存在产品中,很难完全消除;
- 损失了产品的商业利益,这个是直接的经济损失。
推荐方法
基于内容推荐
用户画像
用户画像应该给机器看,而不是给人看。
用户画像是将用户向量化后的结果,其关键因素:维度和量化。
维度:
- 每个维度的名称是可理解的
- 维度的数目是拍脑袋决定的
- 维度的筛选也是拍脑袋决定的
维度越多越精细,但是计算代价会变大,同时也会引入噪声
量化:
不要为了用户画像而用户画像,它只是推荐系统的一个副产品,所以要根据推荐效果(排序好坏、召回覆盖等指标)来指导用户画像量化。
用户画像构建方法
- 直接使用原始数据。比如人口统计学信息、购买历史、浏览历史等。
- 堆数据。堆积历史数据,做统计工作,常用的比如兴趣标签。
- 机器学习方法,比如隐语义模型、矩阵分解等embedding,构建无法直观理解的稠密向量。
从文本数据中挖掘用户画像
- 用户:昵称、姓名、性别、动态、评论等
- 物品:标题、描述、内容等
构建用户画像步骤
- 分析用户的文本和物品的文本,使其结构化;
- 标签选择,为用户挑选有信息量的结构化数据,作为其画像内容。
结构化文本算法
- 关键词提取:TF-IDF、TextRank。
- 实体识别NER:常用基于词典的方法结合 CRF 模型。
- 内容分类:将文本按照频道体系分类,用分类来表达较粗粒度的结构化信息。短文本常用Facebook 开源的 FastText。
- 聚类:无监督聚类,分簇,使用编号
- 主题模型:LDA
- 编码embedding
实体识别还有比较实用化的非模型做法:词典法。提前准备好各种实体的词典,使用trie-tree结构存储,拿着分好的词去词典寻找。
工业级工具:spaCy
LDA工具:Gensim和PLDA等
标签选择
通过户端的文本,物品端的文本如何结构化,得到了诸如标签(关键词、分类等)、主题、词嵌入向量。接下来就是第二步:如何把物品的结构化信息给用户呢?
我们把用户对物品的行为,消费或者没有消费看成是一个分类问题。用户用实际行动帮我们标注了若干数据,那么挑选出他实际感兴趣的特性就变成了特征选择问题。
最常用的是两个方法:卡方检验(CHI)和信息增益(IG)。基本思想是:
- 把物品的结构化内容看成文档;
- 把用户对物品的行为看成是类别;
- 每个用户看见过的物品就是一个文本集合;
- 在这个文本集合上使用特征选择算法选出每个用户关心的东西。
卡方检验
| 卡方检验 | 属于类别C_j | 不属于类别C_j | 总计 |
|---|---|---|---|
| 包含词W_i | A | B | A+B |
| 不包含词W_i | C | D | C+D |
| 总计 | A+C | B+D | N = A+B+C+D |
计算每一个词和每一个类别的卡方值:
- 每个词和每个类别都要计算,只要对其中一个类别有帮助的词都应该留下;
- 由于是比较卡方值的大小,所以公式中的 N 可以不参与计算,因为它对每个词都一样,就是总的文本数;
- 卡方值越大,意味着偏离“词和类别相互独立”的假设越远,靠“词和类别互相不独立”这个备择假设越近。
误区: 基于内容的推荐系统,标签只是很小一部分。而且就算是标签,衡量质量的方式也不是数目够不够。
所谓的基于内容推荐,通俗一点来讲,就是一个包装成推荐系统的信息检索系统。这听上去有点残酷,但通常一个复杂的推荐系统很可能是从基于内容推荐成长起来的。
为什么基于内容的推荐系统这么重要呢?因为内容数据非常易得,哪怕是在一个产品刚刚上线,用心找的话总能找到一些可以使用的内容,不需要有用户行为数据就能够做出推荐系统的第一版。
要把基于内容的推荐做好,需要做好“抓、洗、挖、算”四门功课。它们分别是:
- 抓:一直持续抓数据丰富自己的内容,所以做好一个基于内容的推荐,抓取数据补充内容源,增加分析的维度,两者必不可少。
- 洗:冗余的内容、垃圾内容、政治色情等敏感内容等等都需要被洗出去。
- 挖:很多推荐系统提升效果并不是用了更复杂的推荐算法,而是对内容的挖掘做得更加深入。
- 算:匹配用户的兴趣和物品的属性,计算出更合理的相关性,这是推荐系统本身的使命,不仅仅是基于内容的推荐才要做的。
结合基于内容推荐的框架看上诉几个步骤

内容这一端:内容源经过内容分析,得到结构化的内容库和内容模型,也就是物品画像。用户这一端:用户看过推荐列表后,会产生用户行为数据,结合物品画像,经过用户分析得到用户画像。
内容分析的产出
- 结构化内容库
- 内容分析模型
结构化的内容库,最重要的用途是结合用户反馈行为去学习用户画像。容易被忽略的是第二个用途,在内容分析过程中得到的模型,比如说:- 分类器模型;
- 主题模型;
- 实体识别模型;
- 嵌入模型。
这些模型主要用在:当新的物品刚刚进入时,需要实时地被推荐出去,这时候对内容的实时分析,提取结构化内容,再于用户画像匹配。
内容推荐算法
- 直接计算相似度,BM25F算法
- 转为预估问题、分类问题
一种最典型的场景:提高某种行为的转化率,如点击、收藏、转发等。那么标准的做法是:收集这类行为的日志数据,转换成训练样本,训练预估模型。
每一条样本由两部分构成:一部分是特征,包含用户端的画像内容,物品端的结构化内容,可选的还有日志记录时一些上下文场景信息,如时间、地理位置、设备等等,另一部分就是用户行为,作为标注信息,包含“有反馈”和“无反馈”两类。
二分类:LR+GBDT
协同过滤
User-based CF
$S(u, K)$ 和用户 $ u $ 兴趣最接近的K个用户,$N(i)$ 是对物品i有过行为的用户集合,$w{uv} $ 用户u和v之间的相似度,$ r{ui} $ 用户v对物品i的兴趣,一般为{0,N}
用户相似度计算
用户向量
- 向量的维度就是物品的个数;
- 向量是稀疏的,也就是说并不是每个维度上都有数值,原因当然很简单,这个用户并不是消费过所有物品,废话嘛,连我们压箱底的都给用户推荐了,那当然不用再推荐什么了;
- 向量维度上的取值可以是简单的 0 或者 1,也就是布尔值,1 表示喜欢过,0 表示没有,当然因为是稀疏向量,所以取值为 0 的就忽略了。
Jaccard相似性
余弦相似性
用户间相似度改进:惩罚热门
两个用户对冷门物品采取过同样的行为更能说明他们兴趣的相似度
对两两用户都利用余弦相似度计算相似度。这种方法的时间复杂度是O(|U|*|U|),这在用户数很大时非常耗时,可以采用物品到用户的倒排表。
存在问题及解决
- 构造矩阵:采用稀疏矩阵存储,COO(行号,列号,数值)
- 相似度计算:数据量大时处理
第一个办法是:将相似度计算拆成 Map Reduce 任务,将原始矩阵 Map 成键为用户对,值为两个用户对同一个物品的评分之积,Reduce 阶段对这些乘积再求和,Map Reduce 任务结束后再对这些值归一化;
map: <
reduce:求和并归一化
第二个办法是:不用基于用户的协同过滤,采用基于图的算法。
另外,这种计算对象两两之间的相似度的任务,如果数据量不大,一般来说不超过百万个,然后矩阵又是稀疏的,那么有很多单机版本的工具其实更快,比如 KGraph、 GraphCHI 等。
- 推荐计算
得到了用户之间的相似度之后。接下来还有一个硬骨头,计算推荐分数。显然,为每一个用户计算每一个物品的推荐分数,计算次数是矩阵的所有元素个数,这个代价,你当然不能接受啊。
采用MapReduce
- 遍历每个用户喜欢的物品列表;
- 获取该用户的相似用户列表;
- 把每一个喜欢的物品 Map 成两个记录发射出去,一个是键为 < 相似用户 ID,物品 ID,1> 三元组,可以拼成一个字符串,值为 < 相似度 >,另一个是键为 < 相似用户 ID,物品 ID,0> 三元组,值为 < 喜欢程度 * 相似度 >,其中的 1 和 0 为了区分两者,在最后一步中会用到;
- Reduce 阶段,求和后输出;
- < 相似用户 ID,物品 ID, 0> 的值除以 < 相似用户 ID,物品 ID, 1> 的值
3:
- < 相似用户 ID,物品 ID,1 > -> w_{uv}
- < 相似用户 ID,物品 ID,0 > -> w{uv}*r{vi}
4: reduce应该是对相似用户求和
5:做归一化处理
Item-CF
物品相似度计算
注:相似度计算基于的是评分矩阵或者布尔化的行为矩阵
Jaccard
物品去中心化
用户去中心化
更一般的相似性计算,比如余弦
- 热门关联
- 对热门的打压$ \alpha $ 为0 最大限度打压热门,为1 不打压
- 用户打压IUF(Inverse User Frequence)
- 热传导
冷门受益
热门受益
看除的分母,热门物品度大,冷门度小
调和
矩阵分解/隐语义模型LFM(latent factor model)
评分预测问题只是很典型,其实并不大众,毕竟在实际的应用中,评分数据很难收集到,属于典型的精英问题;与之相对的另一类问题行为预测,才是平民级推荐问题,处处可见。
近邻模型存在的问题:
- 物品之间存在相关性,信息量并不随着向量维度增加而线性增加;
- 矩阵元素稀疏,计算结果不稳定,增减一个向量维度,导致近邻结果差异很大的情况存在。
矩阵分解的目的分解评分矩阵A
推荐过程
$ p_u $ 用户向量,$ q_i $ 物品向量。
基本SVD
SVD(奇异值分解)的损失函数:
SVD学习过程
- 准备好用户物品的评分矩阵,每一条评分数据看做一条训练样本;
- 给分解后的 U 矩阵和 V 矩阵随机初始化元素值;
- 用 U 和 V 计算预测后的分数;
- 计算预测的分数和实际的分数误差;
- 按照梯度下降的方向更新 U 和 V 中的元素值;
- 重复步骤 3 到 5,直到达到停止条件。
增加偏置
分别为全局评分、物品偏置、用户偏置
偏置的计算为,当前评分-对应的平均分
对应的损失函数
增加隐式数据/历史行为
在 SVD 中结合用户的隐式反馈行为和属性,这套模型叫做 SVD++。
隐式反馈的加入方法:
除了假设评分矩阵中的物品有一个隐因子向量外,用户有过行为的物品集合也都有一个隐因子向量,维度是一样的。把用户操作过的物品隐因子向量加起来,用来表达用户的兴趣偏好。
类似的,用户属性,全都转换成 0-1 型的特征后,对每一个特征也假设都存在一个同样维度的隐因子向量,一个用户的所有属性对应的隐因子向量相加,也代表了他的一些偏好。
综合两者,SVD++ 的目标函数中,只需要把推荐分数预测部分稍作修改,原来的用户向量那部分增加了隐式反馈向量和用户属性向量:
加入时间因素
- 对评分按照时间加权,让久远的评分更趋近平均值;
- 对评分时间划分区间,不同的时间区间内分别学习出隐因子向量,使用时按照区间使用对应的隐因子向量来计算;
- 对特殊的期间,如节日、周末等训练对应的隐因子向量。
损失函数优化方法
SGD V.S. ALS
ALS的思想就是固定一个优化另外一个,所以叫交替最小二乘。其好处:
- 在交替的其中一步,也就是假设已知其中一个矩阵求解另一个时,要优化的参数是很容易并行化的;
- 在不那么稀疏的数据集合上,交替最小二乘通常比随机梯度下降要更快地得到结果,事实上这一点就是我马上要说的,也就是关于隐式反馈的内容。
相比“预测用户会打多少分”,“预测用户会不会去浏览”更加有意义,而且,用户浏览数据远远多于打分评价数据。也就是说,实际上推荐系统关注的是预测行为,行为也就是一再强调的隐式反馈。
对隐式反馈的矩阵分解,需要将交替最小二乘做一些改进,改进后的算法叫做加权交替最小二乘:Weighted-ALS。
- 如果用户对物品无隐式反馈则认为评分是 0;
- 如果用户对物品有至少一次隐式反馈则认为评分是 1,次数作为该评分的置信度。
目标函数通常还要防止过拟合,加上正则项,正则项其实认为模型参数还有个先验概率,这是贝叶斯学派的观点,也是 BPR 这个名字中“贝叶斯”的来历。
BPR 认为模型的先验概率符合正态分布,对应到正则化方法就是 L2 正则,具体参见[贝叶斯个性化排序算法小结](https://www.cnblogs.com/pinard/p/9128682.html)。 $$ \prod_{u \in U} P(>_u|\theta) P(\theta) = \prod_{(u,i,j) \in D} \sigma(X_{u12}) P(\theta) = \prod_{(u,i,j) \in D} \sigma(\overline{x}\_{ui} - \overline{x}\_{uj}) P(\theta) $$ 训练方法:梯度下降+mini-batch # 特征工程 实施特征工程之前,需要先理解业务。 在推荐场景中 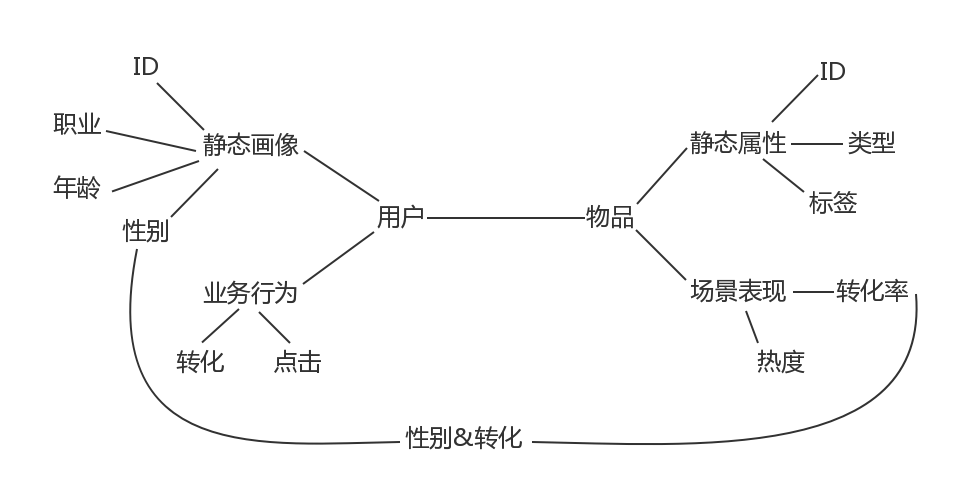 特征 - 先归一化,统一量纲 - 离散化,引入非线性关系 - 特征交叉 - GBDT 无个性化特征信息交叉会造成所有用户结果一样。 交叉特征: - 性别&分布(转化分布) - 分布&ID 在样本给定下: 1. 仔细考虑用何种特征构造方法 2. 从聚合/内积开始,逐渐增加参数,直到过拟合 过拟合判断方法:如,训练集AUC远大于测试集AUC # 模型融合 推荐系统在技术实现上一般划分为三个阶段:挖掘、召回、排序。 挖掘的工作就是对用户和物品做非常深入的结构化分析,庖丁解牛一样,各个角度各个层面的特征都被呈现出来,并且建好索引,供召回阶段使用,大部分挖掘工作都是离线进行的。 接下来就是召回,为什么会有召回?因为物品太多了,每次给一个用户计算推荐结果时,如果对全部物品挨个计算,那将是一场灾难,取而代之的是用一些手段从全量的物品中筛选出一部分比较靠谱的。 最后就是排序,针对筛选出的一部分靠谱的做一个统一的排序。 进一步召回: 在召回阶段,其实就是各种简单的、复杂的推荐算法,比如说基于内容的推荐,会产生一些推荐结果,比如基于物品的协同过滤会产生一些结果,矩阵分解会产生一些结果,等等。 正则化的方法一般是:限定总的树个数、树的深度、以及叶子节点的权重大小。实数特征的分裂。 推荐系统:唯快不破 在线算法 - [FTRL](https://zhuanlan.zhihu.com/p/20447450) - TG - FOBOS - RDA [Boosting For Transfer Learning](http://www.cs.ust.hk/~qyang/Docs/2007/tradaboost.pdf) 特征组合 - GBDT+LR - FM(Factorization Machine):因子分解机 - FFM(Field-aware Factorization Machine) - [Wide & Deep 模型](https://github.com/tensorflow/models/tree/master/official/wide_deep)- 深宽模型是一个结合了传统线性模型和深度模型的工程创新。
- 这个模型适合高维稀疏特征的推荐场景,稀疏特征的可解释性加上深度模型的泛化性能,双剑合璧。
- 这个模型已经开源在 TensorFlow 中。
- 为了提高模型的训练效率,每一次并不从头开始训练,而是用上一次模型参数来初始化当前模型的参数。
- 将类别型特征先做嵌入学习,再将嵌入稠密向量送入深度模型中。
- 为了提高服务的响应效率,对每次请求要计算的多个候选 App 采用并行评分计算的方式,大大降低响应时间。
MAB问题
多臂赌博机问题 (Multi-armed bandit problem, K-armed bandit problem, MAB),简称 MAB 问题。
推荐系统的使命就是:为用户匹配到最佳的物品,在某个时间某个位置为用户选择最好的物品。
推荐就是选择
Bandit 算法
小心翼翼地试,越确定某个选择好,就多选择它,越确定某个选择差,就越来越少选择它。
一种走一步看一步的推荐算法, Bandit 算法。Bandit 算法把每个用户看成一个多变的环境,待推荐的物品就如同赌场里老虎机的摇臂,如果推荐了符合用户心目中喜欢的,就好比是从一台老虎机中摇出了金币一样。
Bandit 算法有汤普森采样,UCB 算法,Epsilon 贪婪。汤普森采样以实现简单和效果显著而被人民群众爱戴,你需要时不妨首先试试它。
Bandit解决冷启动
用分类或者 Topic 来表示每个用户兴趣,我们可以通过几次试验,来刻画出新用户心目中对每个 Topic 的感兴趣概率。
这里,如果用户对某个 Topic 感兴趣,就表示我们得到了收益,如果推给了它不感兴趣的 Topic,推荐系统就表示很遗憾 (regret) 了。
当一个新用户来了,针对这个用户,我们用汤普森采样为每一个 Topic 采样一个随机数,排序后,输出采样值 Top N 的推荐 Item。注意,这里一次选择了 Top N 个候选臂。
等着获取用户的反馈,没有反馈则更新对应 Topic 的 b 值,点击了则更新对应 Topic 的 a 值。
LinUCB
“Yahoo!”的科学家们在 2010 年基于 UCB 提出了 LinUCB 算法,它和传统的 UCB 算法相比,最大的改进就是加入了特征信息,每次估算每个候选的置信区间,不再仅仅是根据实验,而是根据特征信息来估算,这一点就非常的“机器学习”了。
优点:
- 由于加入了特征,所以收敛比 UCB 更快,也就是比 UCB 更快见效;
- 各个候选臂之间参数是独立的,可以互相不影响地更新参数;
- 由于参与计算的是特征,所以可以处理动态的推荐候选池,编辑可以增删文章;
LinUCB 只是一个推荐框架,可以将这个框架应用在很多地方,比如投放广告,为用户选择兴趣标签等。
COFIBA 算法
概要:
- 在时刻 t,有一个用户来访问推荐系统,推荐系统需要从已有的候选池子中挑一个最佳的物品推荐给他,然后观察他的反馈,用观察到的反馈来更新挑选策略。
- 这里的每个物品都有一个特征向量,所以这里的 Bandit 算法是 context 相关的,只不过这里虽然是给每个用户维护一套参数,但实际上是由用户所在的聚类类簇一起决定结果的。
- 这里依然是用岭回归去拟合用户的权重向量,用于预测用户对每个物品的可能反馈(payoff),这一点和我们上一次介绍的 LinUCB 算法是一样的。
与linUCB算法的不同:
- 基于用户聚类挑选最佳的物品,即相似用户集体动态决策;
- 基于用户的反馈情况调整用户和物品的聚类结果。
算法流程:
- 首先计算用户 i 的 Bandit 参数 W,做法和 LinUCB 算法相同,但是这个参数并不直接参与到选择决策中,注意这和 LinUCB 不同,只是用来更新用户聚类。
- 遍历候选物品,每一个物品已经表示成一个向量 x 了。
- 每一个物品都对应一个物品聚类类簇,每一个物品类簇对应一个全量用户聚类结果,所以遍历到每一个物品时,就可以判断出当前用户在当前物品面前,自己属于哪个用户聚类类簇,然后把对应类簇中每个用户的 M 矩阵 (对应 LinUCB 里面的 A 矩阵),b 向量(表示收益向量,对应 LinUCB 里面的 b 向量)加起来,从而针对这个类簇求解一个岭回归参数(类似 LinUCB 里面单独针对每个用户所做),同时计算其收益预测值和置信区间上边界。
- 每个待推荐的物品都得到一个预测值及置信区间上界,挑出那个上边界最大的物品作为推荐结果。
- 观察用户的真实反馈,然后更新用户自己的 M 矩阵和 b 向量,只更新每个用户,对应类簇里其他的不更新。
Bandit 算法系列,主要是解决推荐系统中的冷启动和 EE 问题。探索和利用这一对矛盾一直客观存在,而 Bandit 算法是公认的一种比较好的解决 EE 问题的方案。
深度学习在推荐上的应用
排行榜的构建
热度计算
- Hacker News
- P:得票数,去掉帖子作者自己投票。
- T:帖子距离现在的小时数,加上帖子发布到被转帖至 Hacker News 的平均时长。
- G:帖子热度的重力因子。
公式中,分子是简单的帖子数统计,一个小技巧是去掉了作者自己的投票。分母就是将前面说到的时间因素考虑在内,随着帖子的发表时间增加,分母会逐渐增大,帖子的热门程度分数会逐渐降低。
- 牛顿冷却定律
- H:为环境维度,可以认为是平均票数,比如电商中的平均销量,由于不影响排序,可以不使用。
- C:为净剩票数,即时刻 t 物品已经得到的票数,也就是那个最朴素的统计量,比如商品的销量。
- t:为物品存在时间,一般以小时为单位。
- \alpha:是冷却系数,反映物品自然冷却的快慢。
其他算法
加权采样算法
有限数据集
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!