基于句法依存树的信息抽取
信息抽取是一个常见的nlp任务,为经常一起提到的知识图谱的基础。
这里有一份比较好的知识图谱入门资料:
Mining Knowledge Graphs from Text
信息抽取分为有监督和无监督方法。实际中监督信息往往是缺失的,所以本文主要提无监督方法。
在无监督方法中,一个广泛采用的工具是句法依存树,或者叫句法解析树(Dependency Tree)。
可视化工具:
工作中总结出来的一种基于句法解析树的信息提取的一般方法(尚未完善):
- 从CONLL格式的句法依存解析结果,生成具备孩子节点和父节点索引的树,并获取根结点root_id;
- 自上而下递归的进行解析,孩子节点的解析结果上传到父节点进行汇总;
- 如果当前节点为叶子节点(无孩子节点),判断当前节点类型,返回dict,上传给父节点;
- 如果当前词为动词(一般句子的核心是动词,一般方法也都是从动词开始扩展)或者用户指定的目标词,根据制定的规则提取指定关系类型的孩子,如定中关系、状中关系、动宾关系、主谓关系等,这里需要注意的是并列关系,有可能是补充,有可能是同级并列;
- 如果当前词非动词,先判断其所属信息类型,若能判断,关系向孩子传递,如不能判断,等待孩子节点上传的结果;
- 合并所有孩子的信息,按原始句子顺序排序
- 修正后处理
以提取文本中,关于道路信息的(时间、原因、地点、时间)四元组为例,输入句子:
黄石高速:因交通管制,晋州站、辛集站、藁城东站双向关闭。因沧州服务区附近K81处黄骅方向发生交通事故,沧州服务区附近K81处黄骅方向车辆缓慢通行约4公里句法解析树:
1 黄石 黄石 nh nr _ 3 SBV _ _
2 高速 高速 d d _ 3 ADV _ _
3 : : v v _ 0 HED _ _
4 因 因 p p _ 14 ADV _ _
5 交通管制 交通管制 v v _ 4 POB _ _
6 , , wp w _ 4 WP _ _
7 晋州站 晋州站 ns ns _ 14 SBV _ _
8 、 、 wp w _ 9 WP _ _
9 辛集站 辛集站 n n _ 7 COO _ _
10 、 、 wp w _ 12 WP _ _
11 藁城 藁城 ns ns _ 12 ATT _ _
12 东站 东站 n n _ 7 COO _ _
13 双向 双向 d d _ 14 ADV _ _
14 关闭 关闭 v v _ 3 COO _ _
15 。 。 wp w _ 3 WP _ _
16 因 因 p p _ 24 ADV _ _
17 沧州 沧州 ns ns _ 18 ATT _ _
18 服务区 服务区 n n _ 19 ATT _ _
19 附近 附近 nd f _ 21 ATT _ _
20 K81 K81 ws nx _ 21 ATT _ _
21 处 处 n n _ 22 ATT _ _
22 黄骅 黄骅 ns ns _ 23 ATT _ _
23 方向 方向 n n _ 16 POB _ _
24 发生 发生 v v _ 3 COO _ _
25 交通事故 交通事故 n n _ 24 VOB _ _
26 , , wp w _ 24 WP _ _
27 沧州 沧州 ns ns _ 28 ATT _ _
28 服务区 服务区 n n _ 29 ATT _ _
29 附近 附近 nd f _ 31 ATT _ _
30 K81 K81 ws nx _ 31 ATT _ _
31 处 处 n n _ 34 ATT _ _
32 黄骅 黄骅 ns ns _ 33 ATT _ _
33 方向 方向 n n _ 34 ATT _ _
34 车辆 车辆 n n _ 36 SBV _ _
35 缓慢 缓慢 a ad _ 36 ADV _ _
36 通行 通行 v v _ 24 COO _ _
37 约 约 d d _ 38 ATT _ _
38 4 4 m m _ 39 ATT _ _
39 公里 公里 q q _ 36 CMP _ _
40 。 。 wp w _ 3 WP _ _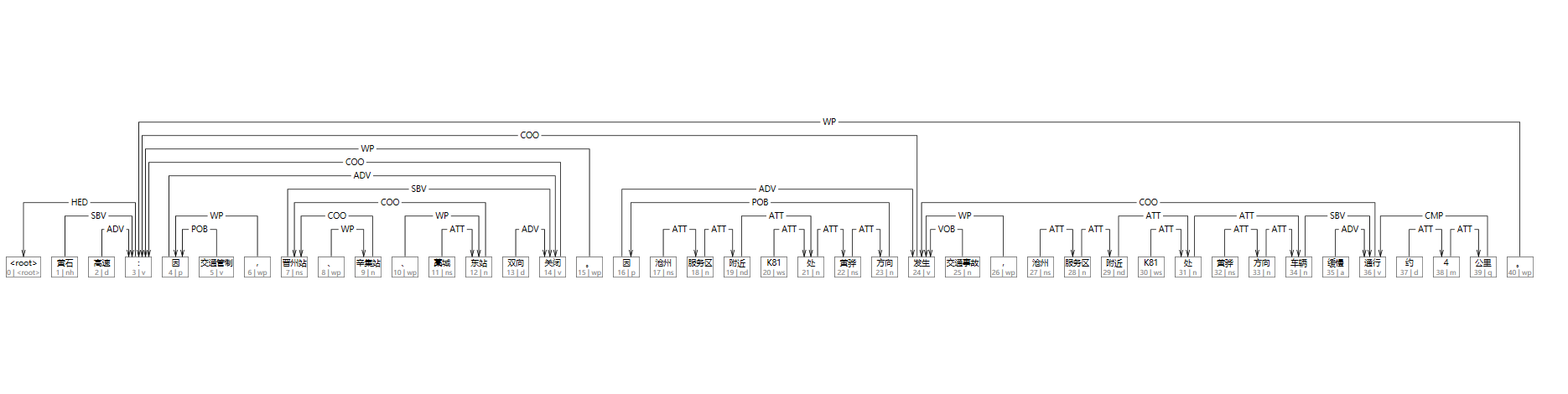
核心代码如下:
class WordBean(object):
''' 扩展conllword,存储父节点与孩子节点索引 '''
def __init__(self):
self.lemma = None
self.postag = None
self.relation = None
self.head_id = None
self.flag = True # 是否还处于树中标志位,已合并的ATT将置为False
self.child = []
def set_word(self, conll_word):
self.lemma = conll_word.LEMMA
self.postag = conll_word.POSTAG
self.relation = conll_word.DEPREL
self.head_id = conll_word.HEAD.ID - 1
def add_child(self, child_id, child_relation):
self.child.append((child_id, child_relation))
def extract_entity_tuple(self, dependency_tree, seed_id, head_type=''):
'''自上而下解析树'''
res_entity_tuple_list = []
res_dict = dict()
res_dict['time'] = []
res_dict['reason'] = []
res_dict['place'] = []
res_dict['status'] = []
# 判断是否是叶子节点
if len(dependency_tree[seed_id].child) == 0:
if dependency_tree[seed_id].lemma in self.status_set:
res_dict['status'].append((seed_id, dependency_tree[seed_id].lemma))
elif self.check_is_time(dependency_tree, seed_id):
res_dict['time'].append((seed_id, dependency_tree[seed_id].lemma))
elif head_type == 'reason':
res_dict['reason'].append((seed_id, dependency_tree[seed_id].lemma))
elif head_type == 'time':
res_dict['time'].append((seed_id, dependency_tree[seed_id].lemma))
else:
if not dependency_tree[seed_id].lemma in self.discard_word_set:
res_dict['place'].append((seed_id, dependency_tree[seed_id].lemma))
res_entity_tuple_list.append(res_dict)
return res_entity_tuple_list
# 非叶子节点需要向下递归解析
if dependency_tree[seed_id].lemma in self.status_set:
# 当前节点为状态节点
status_merge_list = []
for c_id, c_relation in dependency_tree[seed_id].child:
child_bean = dependency_tree[c_id]
if c_relation in ('COO', '并列关系'):
# 假设状态下不存在嵌套状态,有视为补充
if dependency_tree[c_id].postag == 'v' and len(dependency_tree[c_id].child) == 0:
res_dict['status'].append((c_id, dependency_tree[c_id].lemma))
else:
child_dict_list = self.extract_entity_tuple(dependency_tree, c_id)
for child_dict in child_dict_list:
self.merge_two_tuple_dict(res_dict, child_dict)
elif c_relation in ('ADV', '状中结构'):
# 处理状中结构
if child_bean.lemma in ('因', '受', '由于'):
# 处理原因
child_dict_list = self.extract_entity_tuple(dependency_tree, c_id)
for child_dict in child_dict_list:
self.merge_two_tuple_dict(res_dict, child_dict)
elif child_bean.lemma == '处' or child_bean.postag == 'p':
child_dict_list = self.extract_entity_tuple(dependency_tree, c_id)
for child_dict in child_dict_list:
self.merge_two_tuple_dict(res_dict, child_dict)
elif child_bean.postag in ('a', 'ad', 'd'):
self.merge_att(dependency_tree, c_id)
status_merge_list.append(c_id)
elif self.check_is_time(dependency_tree, c_id):
self.merge_att(dependency_tree, c_id)
res_dict['time'].append((c_id, dependency_tree[c_id].lemma))
elif c_relation in ('POB', '介宾关系') and
child_bean.lemma in ('因', '受', '由于'):
self.merge_att(dependency_tree, c_id)
res_dict['reason'].append((c_id, dependency_tree[c_id].lemma))
elif c_relation in ('CMP', '动补结构'):
self.merge_att(dependency_tree, c_id)
status_merge_list.append(c_id)
elif c_relation in ('SBV', '主谓关系'):
# 处理主谓关系,解析具体地点
child_dict_list = self.extract_entity_tuple(dependency_tree, c_id)
for child_dict in child_dict_list:
self.merge_two_tuple_dict(res_dict, child_dict)
elif c_relation in ('VOB', '动宾关系'):
if len(dependency_tree[c_id].child) == 0:
res_dict['status'].append((c_id, dependency_tree[c_id].lemma))
else:
child_dict_list = self.extract_entity_tuple(dependency_tree, c_id)
for child_dict in child_dict_list:
self.merge_two_tuple_dict(res_dict, child_dict)
status_buffer = []
status_merge_list.append(seed_id)
status_merge_list.sort()
for id in status_merge_list:
status_buffer.append(dependency_tree[id].lemma)
res_dict['status'].append((seed_id, ''.join(status_buffer)))
res_entity_tuple_list.append(res_dict)
return res_entity_tuple_list
else:
# 当前节点为非状态节点
pre_head_type = head_type
if self.check_is_time(dependency_tree, seed_id):
# 为时间节点
head_type = 'time'
res_dict['time'].append((seed_id, dependency_tree[seed_id].lemma))
elif dependency_tree[seed_id].lemma in ('因', '受', '由于') or head_type == 'reason':
# 为原因节点
head_type = 'reason'
res_dict['reason'].append((seed_id, dependency_tree[seed_id].lemma))
else:
if not dependency_tree[seed_id].lemma in self.discard_word_set:
res_dict['place'].append((seed_id, dependency_tree[seed_id].lemma))
child_dict_list = []
coo_list = []
for c_id, c_relation in dependency_tree[seed_id].child:
# if c_relation in ('COO', '并列关系'):
# coo_list.append(c_id)
if c_relation in ('WP', '标点符号'):
continue
else:
if head_type == 'reason' and not pre_head_type == 'reason':
if c_relation in ('POB', '介宾关系'):
child_dict_list.extend(self.extract_entity_tuple(dependency_tree, c_id, head_type))
if dependency_tree[c_id].lemma in self.status_set:
res_dict['reason'].append((c_id, dependency_tree[c_id].lemma))
else:
child_dict_list.extend(self.extract_entity_tuple(dependency_tree, c_id, head_type))
# 先合并非状态
status_dict_list = []
for child_dict in child_dict_list:
if len(child_dict['status']) > 0:
status_dict_list.append(child_dict)
else:
self.merge_two_tuple_dict(res_dict, child_dict)
# 再合并存在状态的
if len(status_dict_list) == 0:
res_entity_tuple_list.append(res_dict)
else:
for child_dict in status_dict_list:
# tmp_dict = res_dict.copy()
tmp_dict = copy.deepcopy(res_dict)
self.merge_two_tuple_dict(tmp_dict, child_dict)
res_entity_tuple_list.append(tmp_dict)
return res_entity_tuple_list
def extract_information(self, line):
segs = self.nlp_tokenizer.seg(line)
# fix segs
self.fix_seged_postag(segs)
conll_words = self.parser.parse(segs).getWordArray()
dependency_tree, root_id = self.construct_dependency_tree(conll_words)
res_entity.append(self.extract_entity_tuple(dependency_tree, i))
res_entity = self.extract_entity_tuple(dependency_tree, root_id)
# print entity tuples
for entity in res_entity:
entity['time'].sort()
entity['place'].sort()
entity['reason'].sort()
entity['status'].sort()
self.fix_entity_tuple_dict(entity)
print(entity)
return res_entity
实验结果:
# 输入句子
'黄石高速:因交通管制,晋州站、辛集站、藁城东站双向关闭。因沧州服务区附近K81处黄骅方向发生交通事故,沧州服务区附近K81处黄骅方向车辆缓慢通行约4公里。'
# 信息提取结果
{'time': [], 'reason': ['因交通管制'], 'place': ['黄石高速:, 晋州站, 辛集站, 藁城东站'], 'status': ['交通管制, 双向关闭']}
{'time': [], 'reason': ['因沧州服务区附近K81处黄骅方向'], 'place': ['黄石高速:, 发生交通事故, 沧州服务区附近K81处黄骅方向'], 'status': ['缓慢通行约4公里']}
可以看到,第一句的解析没问题,但是第二句原因的解析边界出错。当前的解析方法仍然比较依赖于句法依存树的准确性,实体的边界的准确性不够,也是需要改进的地方。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!